dav1d 0.9.1: a ton of asm
dav1d 0.9.0 optimizations about 10bit
Since 0.7.1 release from last year, we’ve focused on optimizing high-bitdepth decoding, on ARM and x86 platforms.
For those who don’t know, high-bitdepth means 10bit and 12bit per pixels instead of 8, which increases the precision of colors and is necessary for UHD and HDR images and videos. (Note: 12bit is very rarely used in consumer cases.)
Because the data uses 10bit per component, we need to write specific assembly code, different from the 8bit code. However, the code written sometimes supports both 10bit and 12bit, because the data structures are using 16bit and adding 12bit does not increase the work.
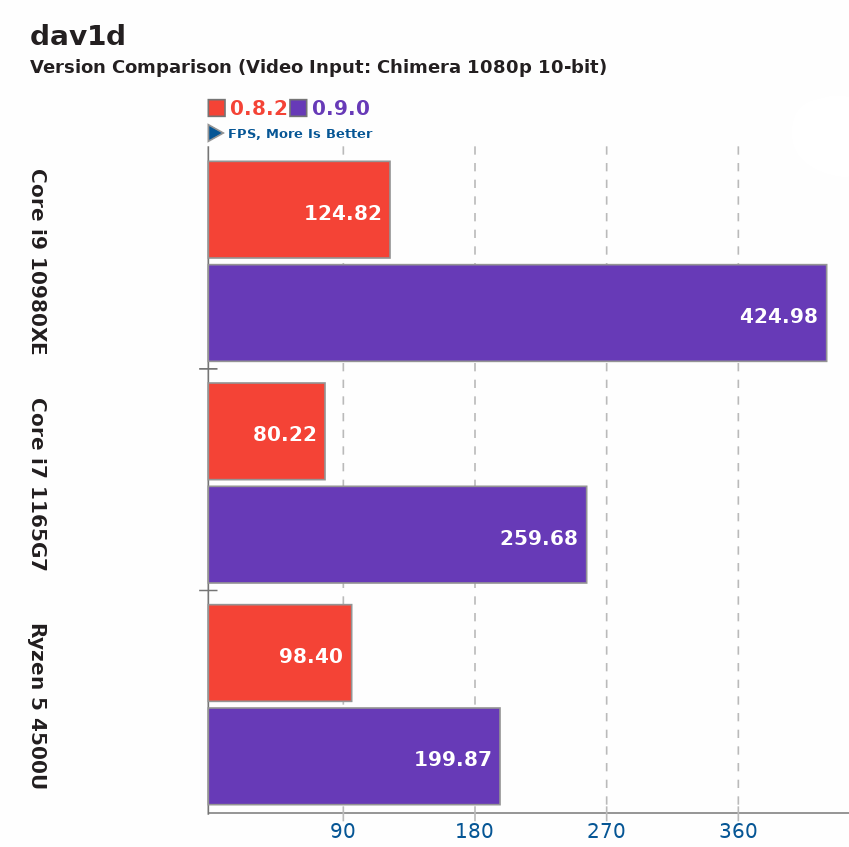
The dav1d releases 0.8.0, 0.8.1, 0.8.2 and 0.9.0 have improved the support of high-bitdepth optimizations in dav1d until 0.9.1, where they are now almost finished.
Optimizations coverage
With 0.9.1, we’ve done most of the optimizations for 8/10/12bit on the following platforms:
- Desktop CPUs with AVX2 (64bit)
- Desktop CPUs with SSSE3 in 32bit
- Desktop CPUs with SSSE3 in 64bit
- ARM CPU in 32bit, ARMv7
- ARM CPU in 64bit, ARMv8
There are still some minor optimizations left to do, but they won’t change much the overall performance of the decoder.
For example, intra z1/z2/z3, 12bit SGR or 12bit itxfm are not done, but their usefulness is debatable :)
Please note also, that some optimizations were done for SSE4 and not SSSE3.
Assembly size
The portion of code in dav1d written in assembly is now reaching 140000 lines of code.
This code is composed of:
- 90000 lines for x86 (AVX2, SSSE3-32, SSSE3-64);
- 50000 lines for ARM (32bit and 64bit).
This is very large for handwritten assembly, and for comparison, this is more assembly than what there is in FFmpeg (for all codecs).
And yes, this code is faster than what the compilers can generate by themselves. :)
The end?
Does this mean that the dav1d project is complete?
Well, yes and no.
Yes, most of the work for the optimizations are done, and this is good news.
However, there is still some major work to be done to improve our threading model; also, there are still some other minor optimizations to be done, and maintenance for new operating systems.