A few reminders about dav1d
If you follow this blog, you should know everything about dav1d.
AV1 is a new video codec by the Alliance for Open Media, composed of most of the important Web companies (Google, Facebook, Netflix, Amazon, Microsoft, Mozilla…). AV1 has the potential to be up to 20% better than the HEVC codec, but the patents license is totally free, while HEVC patents licenses are insanely high and very confusing.
The VideoLAN, VLC and FFmpeg communities have started to work on a new decoder, sponsored by the Alliance for Open Media, in order to create the reference optimized decoder for AV1.
Third major Release
We just released the third version of dav1d, called 0.3.0 Sailfish.
The decoder is ready and being now largely used on all platforms, with excellent performance.
The focus for the first release was for AVX-2 processors, with up to 5x speedups compared to the reference decoder.
The second release was focusing on the other desktop CPU, SSSE3 and on mobile phones (2 to 4x faster) , and a lot more stability.
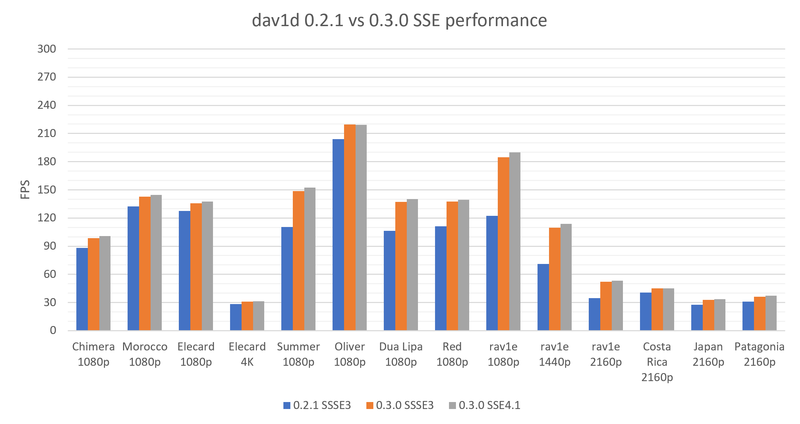
This third release continues to increase the ARM and SSSE3 speed, with more optimizations, as announced, and we get between 12 and 25% speed increases on those CPUs, depending on the samples.
However, more surprisingly, we got a speedup on AVX-2 CPU, by optimizing the MSAC (entropy decoding), while we did not find a good solution in the past. This brings 4-5% speed improvements, which is quite huge, knowing the maturity of the AVX-2 code.
Results
This are the gains we got for SSSE3 compared to the previous release:
And this is where we are, on desktop platforms, compared to aomdec:
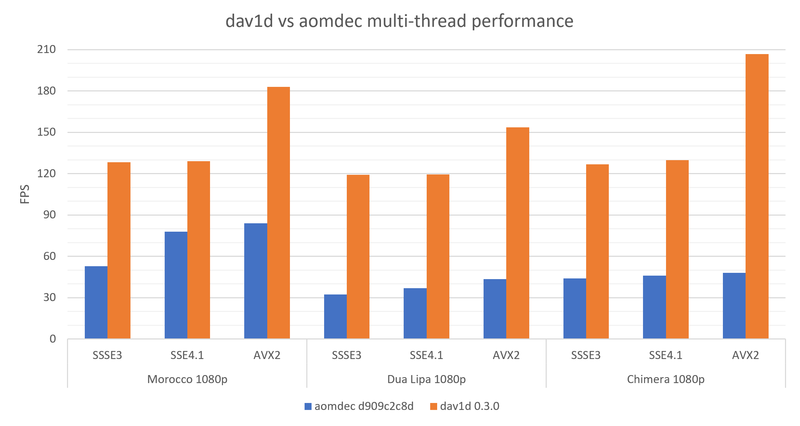
As you can see, we’re now getting consistently 2.5 to 4 times faster on SSSE3, 2 to 5 times faster on AVX-2 compared to aomdec.
On mobiles devices, we’re now also getting 3 to 4 times faster with ARM64 CPU than aomdec. I don’t have a fancy graph, but you can see results here.
What’s next?
What’s next is more complex to foretell: there are still some optimizations to do on SSSE3 and ARM64, but they are getting less important, so the speedups might not be as impressive as those shown today. We might improve AVX-2 still, but we’re talking about a few percents, it’s going to be hard to get more.
We’re also going to toy with compute-shaders for decoding faster, but it’s very hard to know if that’s going to give a speed-up at all.
Keep in touch, and you’ll see!