Release 0.7.1
We just did a small release of dav1d called 0.7.1, just one month after 0.7.0.
It is a quick release that fixes a couple of bugs and that does more optimizations on ARM32 and SSE2.
ARM 32-bit
After spending a lot of time on ARM64 during 0.5.0 and 0.7.0, we’re spending some times for the people who are stuck with older phones, still running on 32-bit platforms.
With these new optimizations, we’re 28% faster than before when decoding the Chimera sample on a Snapdragon 835.
The result is that we’re only 20%-25% slower in 32bit compared to 64bit, which is quite a feast.
Compared to gav1, we’re now 2x-2.4x faster, in 32bit mode.
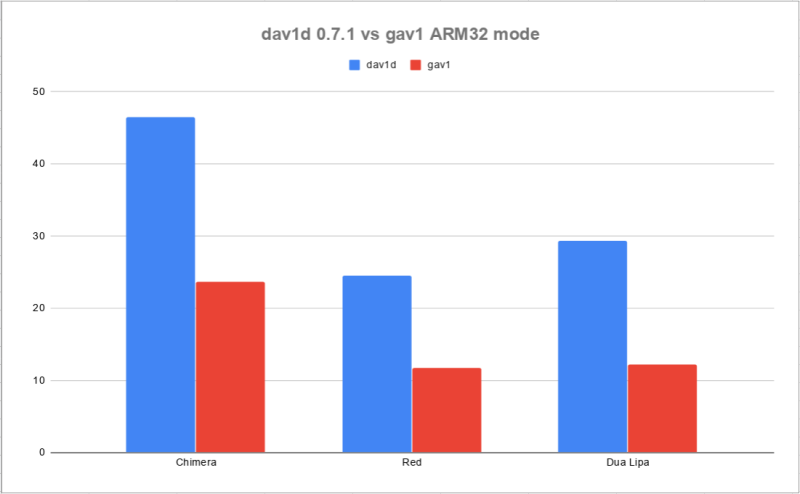
When comparing with numerous threading options, on a Galaxy S5, from 2014, we can see the following:
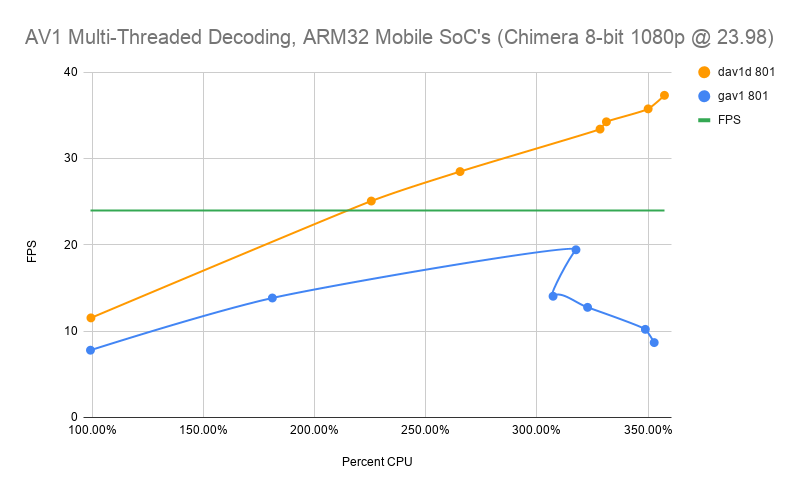
With dav1d 0.7.1, we’re able to decode the AV1 Chimera 1080p sample at more than 24 fps on a Galaxy S5 from 2014 on Android (32-bit)! Reaching 24fps does not even use the full CPU!
Once again, we see that the gav1 library has issues with threading.
Desktop
On the desktop, we did some SSE2 optimizations, for the people who don’t have SSSE3 CPU, which should see quite a bump in decoding.
We also did optimizations for the scaled mode, in AVX2. (This is used only by bitstreams that use the spatial scalability feature).
Conclusion
See you soon, for more speed improvements!
PS: thanks again to Nathan for the graphs.