dav1d shifts up a gear : 0.2 is out!
tl;dr: dav1d has its second release
If you want a quick summary of this post, about our AV1 decoder:
- dav1d is really ready for production,
- dav1d has impressive benchmarks on ARM devices,
- dav1d is now fast on 32-bit desktop processors (SSSE3).
Read the following for more details…
A few reminders about dav1d
If you follow this blog, you should know everything about dav1d.
AV1 is a new video codec by the Alliance for Open Media, composed of most of the important Web companies (Google, Facebook, Netflix, Amazon, Microsoft, Mozilla…). AV1 has the potential to be up to 20% better than the HEVC codec, but the patents license is totally free, while HEVC patents licenses are insanely high and very confusing.
The VideoLAN, VLC and FFmpeg communities have started to work on a new decoder, sponsored by the Alliance for Open Media, in order to create the reference optimized decoder for AV1.
Second Release
Today, we release the second version of dav1d, called 0.2.1, Antelope.
You can now safely use the decoder on all platforms, with excellent performance.
For the first release, we showed impressive benchmarks for AVX-2 processors, with up to 5x speedups compared to the reference decoder.
In this release, the focus has been toward ARM devices (32-bit and 64-bit) and desktop processors that did not support AVX-2.
It is important to know that the ARM and SSSE3 optimizations are not finished yet. You should expect more performance in the future.
ARM devices
For the ARM devices, we’ve been doing both ARMv7 and ARMv8 acceleration. We’ve been testing on iOS, Windows and Android to be sure that it works fine on all OSes.
On ARMv8, we achieve between 150% and 200% of the speed of aomdec:
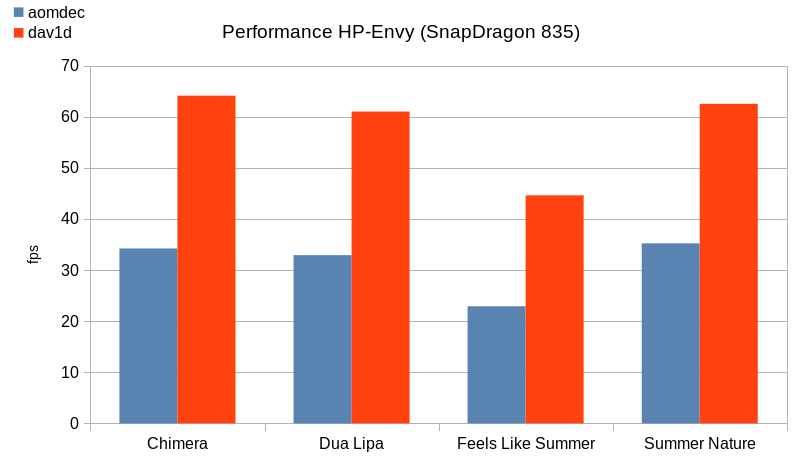
On ARMv7, we achieve up to 400% on the SnapDragon 410:
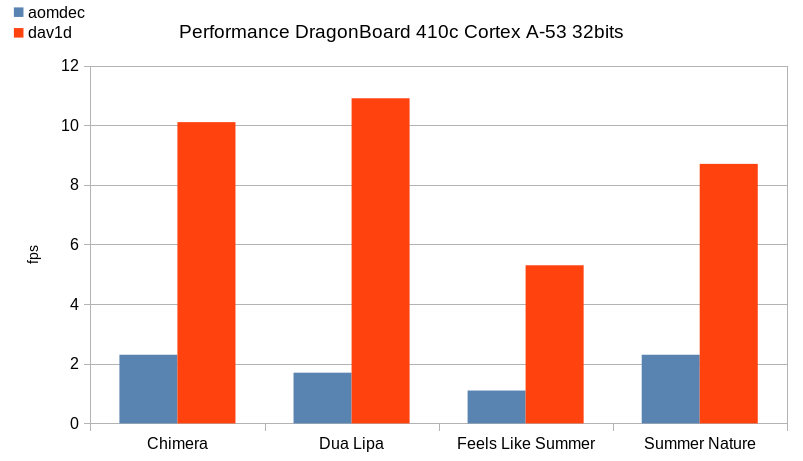
It’s interesting to see that dav1d is faster in ARMv7 mode than the reference decoder in ARMv8 mode on the same machine.
iOS and iPhones
The playback on iOS is quite important, since those are the fastest ARM devices, and quite widespread:
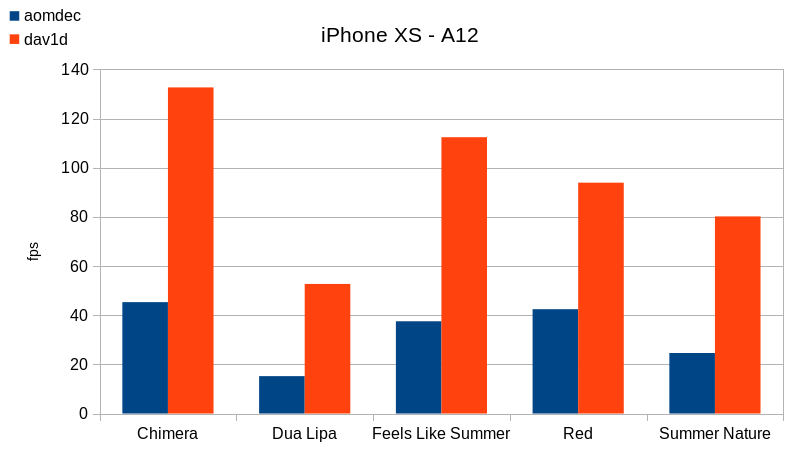
Depending on the samples, we have achieve 1080p at 75fps on Summer sample, and 40fps on more complex samples, like Chimera.
Desktop
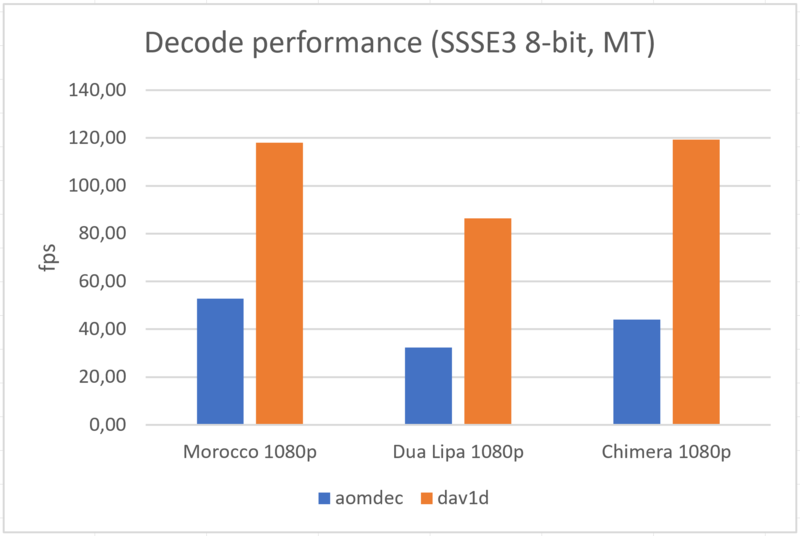
For the desktop, we focused on SSSE3 optimizations, because they should cover 98% active of the desktop processors.
We also did optimizations for both 32-bit and 64-bit architectures, and not only 64bits, as we did for AVX-2.
In multi-thread scenarios, we show between 2x and 3x gains compared to aomdec:
Get it
You can get the tarball on our FTP: dav1d 0.2.1.
You can get the code and report issues on our gitlab project.
You can also join the project, or sponsor our work, by contacting me :)
Conclusion
Dav1d 0.2 is now faster than aomdec on all the 4 important architectures (x86/SSSE3, x64/AVX-2, ARMv7, ARMv8).
The speedups we see goes from x2 and x5, and on ARM devices, we are now approaching 1080p60 in software.
We’re going to continue acceleration work on SSSE3 and ARM devices, in the next few releases.