dav1d 0.5.0 release: fastest!
A few reminders about dav1d
If you follow this blog, you should know everything about dav1d. Two months after 0.4.0, and Four months after the 0.3.0 release, we show our new release: 0.5.0.
AV1 is a new video codec by the Alliance for Open Media, composed of most of the important Web companies (Google, Facebook, Netflix, Microsoft, Mozilla…). AV1 has show to be 20% better than the HEVC codec, but the patents license is totally free, while HEVC patents licenses are very complex to acquire.
The VideoLAN, VLC and FFmpeg communities have started to work on a new decoder, dav1d, to be the best decoder.
0.5.0
The release 0.3.0 was a very solid release, bringing huge gains in performance, and getting AV1 decoding ready for primetime.
0.4.0 (which I did not blog about, sorry) brought 15% gains on ARM64 and notably reduced the RAM usage by half.
This new release, 0.5.0, aka “Asiatic Cheetah”, is bringing even more speed improvements to AV1 decoding.
On AVX-2, I know I said already 2 times that we were at the maximum speed, but we got even faster, notably thanks to improvements on MSAC and CoefDecode. The gains range from 3% to 7% depending on the content.
On SSSE3, we have merged now most of the assembly functions, for both 32-bit and 64-bit architectures. This gives improvements ranging from 20% to 40% on SSSE3.
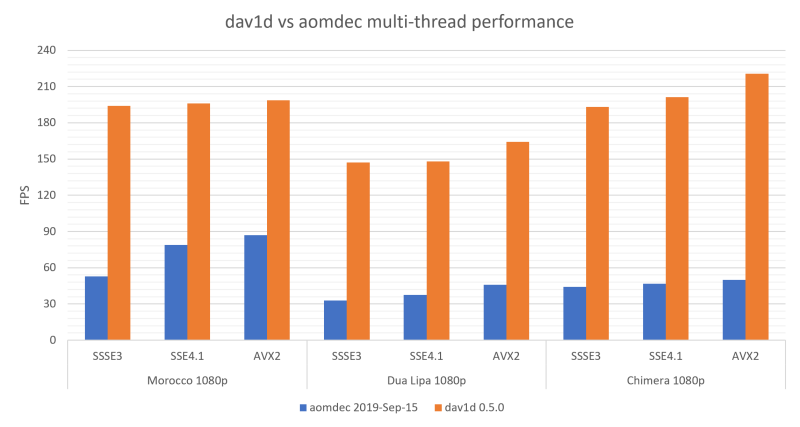
You can now see that our SSSE3 performance is quite close to our AVX-2 performance. This is, of course, very CPU dependent.
Because you shouldn’t blindly believe me, you should really see the Phoronix article on our release.
As you can see, depending on the content, we’re between 3 and 5 times faster than aomdec, and 8 times faster than gav1 on desktop CPUs.
ARM64 performance
On ARM64, for mobile, we’ve continued to merge ASM code too. We’ve done all the major functions in ASM now.
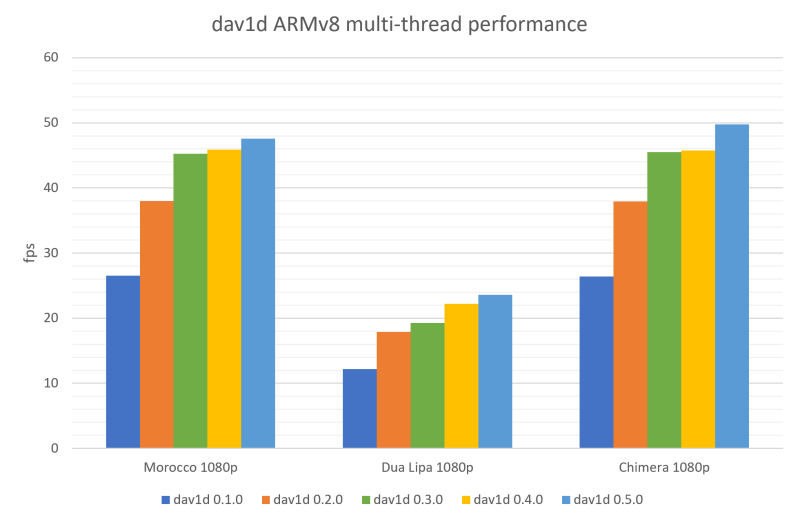
The speed improvements from 0.3.0 to 0.5.0 are close to 15% in Single-Thread. This can give improvements around 20% in Multi-Thread, depending on the CPU and the content.
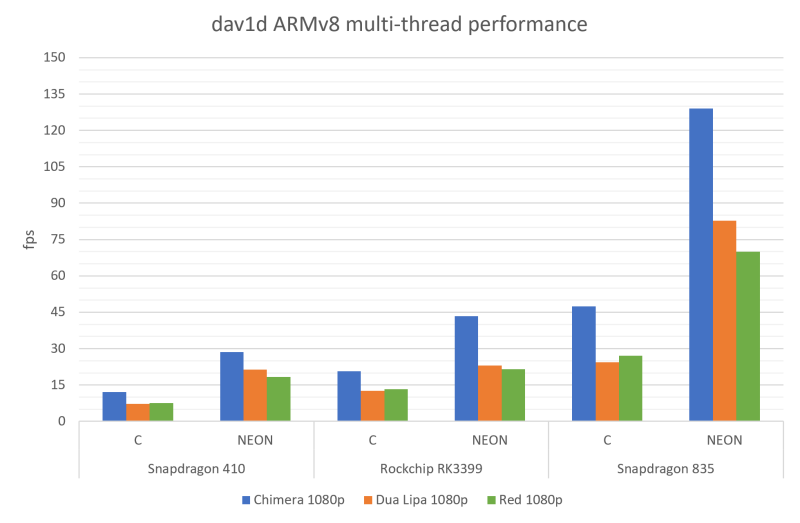
If you look at other ARMv8 CPU, we’re almost at 1080p30 for the Chimera sample:
AV1 decoding on Android: gav1
As you might have heard, there is a new player in town: Google released gav1 decoder, “optimized” for Android.
As you can see here, on ARM64, the architecture of all the recent smartphones, dav1d is beating gav1 quite largely:
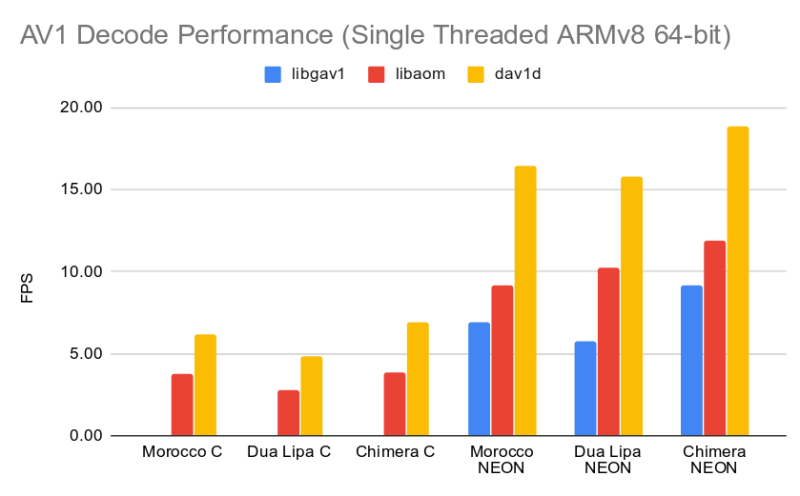
It seems that gav1 is slightly faster on ARM32, but no recent device is running ARM32. So what’s the point?
On iOS, we’ve measured between 30% and 170% increase in Single Thread.
Next?
We need to keep improving, because it will be fun. The next targets for improvements are SSE2 and ARM32, because we still have gains there.
A release in the next 2 months, maybe?